1. Choose a framework
Assuming we use Python to do this.
plain python?
We can write a simple Python crawler with the code below:
import re, urllib
textfile = file('depth_1.txt','wt')
print "Enter the URL you wish to crawl.."
print 'Usage - "http://phocks.org/stumble/creepy/" <-- With the double quotes'
myurl = input("@> ")
for i in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(myurl).read(), re.I):
print i
for ee in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(i).read(), re.I):
print ee
textfile.write(ee+'\n')
textfile.close()
Scrapy?
- You only define the rules, Scrapy do the rest
- easily plugin extensions
- portable + python runtime.
Why Scrapy
scrapy has the tools to manage every stage of a web crawl, just to name a few:
Requests manager - in charge of downloading pages all concurrently behind the scenes! You won’t need to invest a lot of time in concurrent architecture.
Selectors - parse the html document (eg. XPath)
Pipelines - after you retrieve the data, there’s a bunch of functions to modify the data.
Following the spirit of other don’t repeat yourself frameworks, such as Django:
it makes it easier to build and scale large crawling projects by allowing developers to re-use their code.
For more, read Scrapy Architecture .
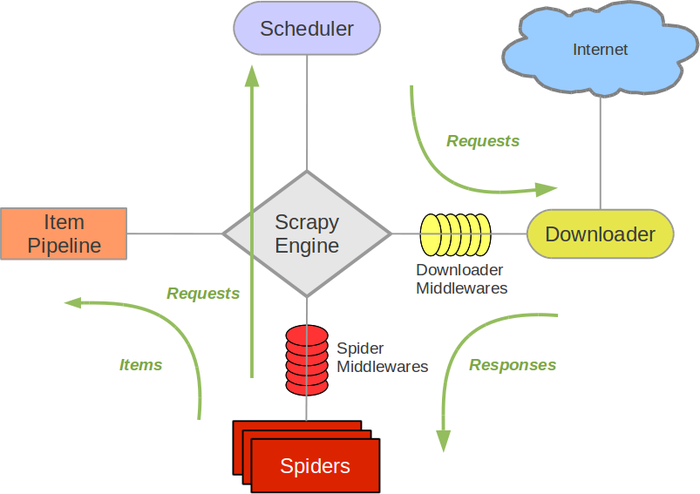
Scrapy Engine
control data flow
Scheduler
receives requests from the engine and enqueues them for feeding them later
Downloader
Spiders
Item Pipeline
Downloader middlewares
specific hooks that sit between the Engine and the Downloader and process requests
Spider middlewares
specific hooks that sit between the Engine and the Spiders and are able to process spider input (responses) and output (items and requests).
2. Schedule a Scrapy job
APScheduler? (todo)
add/remove jobs
3. Choose a DB
I chose NoSQL/MongoDB. But why?
there’s only a few tables with few columns
no overly complex associations between nodes
huge amount of time-based data
scaling requirements: MongoDB better horizontal scaling
different field names: dynamical storage
4. Technical Difficulty?
4.1 differrent way to crawl.
We need to check AJAX response sometime and study each website’s API.
Some site would close certain APIs if they found out too many queries requests.
4.2 Difficulty navigating pages
Study their URL structure.
eg.
www.abc.com/index.html?page=milk&start_index=0
Just play with the url params!
4.3 What is key?
I defined extra column only to store keys (combine a few key columns, and convert to lower-case).
We can search using regex though, but:
Mongo (current version 2.0.0) doesn’t allow case-insensitive searches against indexed fields. For non-indexed fields, the regex search should be fine.
How to go about it:
searching with regex’s case insensitive means that mongodb cannot search by index, so queries against large datasets can take a long time.
Even with small datasets, it’s not very efficient… which could become an issue if you are trying to achieve scale.
As an alternative, you can store an uppercase copy and search against that…
If your field is large, such as a message body, duplicating data is probably not a good option. I believe using an extraneous indexer like Apache Lucene is the best option in that case.
4.4 A lot bad data
write a sophisticated pipeline()
try not let bad data reach pipeline() - better
Make your spider better!
4.5 NLP: brand names
how? (todo)